Reconocimiento Visual
Uttal define el reconocimiento como la acción de clasificar, categorizar o conceptuar un determinado estímulo como miembro de una clase de estímulos. El proceso de reconocimiento es más complejo que los de detección o discriminación:
- El único requisito en la detección es advertir la presencia de un estímulo.
- En la discriminación para poder percibir las semejanzas y diferencias entre estímulos, se añadía un requisito de memoria.
- El reconocimiento requiere el recuerdo de una o varias clases de estímulos. También requiere la asignación de significado al objeto, ya que la acción de clasificar, categorizar o conceptuar depende más del significado que se asigna al objeto que de las características físicas del mismo.
El proceso de reconocimiento es fundamental para el desenvolvimiento de los seres humanos en su interacción con el medio ambiente.
En la actualidad no se dispone de ningún modelo de reconocimiento que pueda resultar tan potente y eficaz como el sistema de reconocimiento visual de los seres humanos.
Reconocimiento de objetos
El mecanismo básico consiste en la comparación de la imagen de un objeto con una representación del objeto almacenada en la memoria.
Para comprender cómo se lleva a cabo la comparación, habrá que conocer:
- Qué tipo de procesos permiten derivar una descripción adecuada de la imagen.
- Cómo se almacena esas descripciones.
- Cómo se realiza la comparación.
Habrá que conocer la relación entre los procesos visuales de descripción de la imagen y los procesos cognitivos que permiten realizar la comparación.
Comparación de plantillas
Las primeras investigaciones sobre reconocimiento visual, se centraron en el reconocimiento de patrones bidimensionales relativamente simples, como letras y números. Una de las propuestas iniciales consistía en suponer que para cada carácter alfanumérico debería haber una plantilla almacenada en la memoria con la cual se compara el patrón.
Un posible forma de reconocimiento, consistiría en comparar la imagen correspondiente a un patrón visual nuevo con la plantilla almacenada en la memoria y determinar si éste encaja o no en la plantilla. El reconocimiento de un nuevo patrón, no familiar o conocido, se realizaría comparándolo con la plantilla y viendo si se ajusta o no a la misma.
Cuanto más se ajustara el patrón a la plantilla, mayor probabilidad de que se reconociera.
El procedimiento de comparación de plantillas, sería útil para el reconocimiento de patrones cuya forma básica es relativamente constante. El reconocimiento de caracteres alfanuméricos utilizando plantillas, resulta mucho más complicado cuando las formas básicas, tamaño y posición varían.
La comparación de plantillas no sería útil para reconocer patrones complejos u objetos naturales, debido a la complejidad y variaciones que éstos presentan.
Los problemas que presenta este procedimiento están fundamentalmente relacionados con su falta de economía. Por atraparte, el reconocimiento no sería posible cuando los patrones cambiasen de orientación, tamaño o posición, o cuando existiera alguna deformación en los mismos.
Una posible solución a este problema requeriría que las imágenes de los objetos fueran sometidas previamente a un proceso de normalización (ajustándose al tamaño, orientación, etc), y una vez normalizados, se compararan con las plantillas almacenadas. Una forma de obtener esta normalización cosiste en complementar la descripción del objeto con información sobre la distancia del objeto y la orientación en relación con el observador.
Análisis de características
Una postura teórica diferente, contempla la posibilidad de que el sistema visual disponga de detectores específicos de características geométricas simples como líneas verticales, horizontales y oblicuas. El reconocimiento se obtendría mediante la detección de las características definitorias de un patrón determinado.
El primer modelo de reconocimiento basado en las características, el “pandemonium”, fue desarrollado por Selfridge.
En el modelo del pandemonium, cada número o letra se representa internamente por una lista de características locales que definen su forma.
Por ejemplo, las características locales de una H, serían dos líneas verticales, una horizontal y cuatro ángulos rectos. Cuando se presenta un patrón nuevo se hace una lista de sus características y se comparan todas a la vez con las listas de características de patrones conocidos almacenadas en la memoria. Si el nuevo patrón se ajusta a alguna de las características se reconocer y se clasifica como perteneciente a una determinada categoría.
El sistema consta de una serie de mecanismo o “demonios”, cada uno de los cuales realiza una función específica. Los “demonios de la imagen” cumplen la función de formar una representación interna del patrón estimular. Los “demonios de las características” analizan la imagen y responden únicamente cuando está presente la característica a la que son sensibles.
Los “demonios cognitivos”, son responsables del reconocimiento de patrones específicos. Su forma de actuar consiste en recoger las respuestas anteriores y buscar combinaciones de características que definen el patrón cuyo reconociendo son responsables. Si encuentran una serie de características pertinentes en relación con un patrón determinado, envían su información al “demonio de la decisión” que tiene como función proporcionar la respuesta final sobre el reconocimiento.
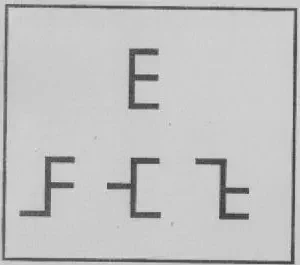
Sin embargo, el mecanismo de reconocimiento propuesto por el modelo del pandemonium no es aplicable en muchos casos. Por ejemplo, para reconocer la letra E tendríamos una lista de características que respondería a una línea vertical y tres líneas horizontales más cortas. El problema es que la lista de características no es suficiente para facilitar el reconocimiento. Por lo tanto, sería necesario especificar las relaciones entre las características elementales.
Una dificultad mayor para este modelo, estaría en relación con el reconocimiento de objetos naturales y patrones más complejos que los caracteres alfanuméricos.
Definir un patrón complejo, como por ejemplo un insecto, en base a este tipo de características resultaría imposible.
Descripciones estructurales
Las descripciones estructurales incluyen además de la descripción de las características de un patrón, las relaciones entre las mismas y su disposición espacial.
La especificación de las relaciones entre las características así como su disposición espacial, permite la comparación de los patrones nuevos con las representaciones almacenadas, obviando la ambigüedad de los procedimientos anteriores.
Sin embargo, la descripción estructural no garantizaría el reconocimiento del objeto en situaciones en las que se produce un cambio en la imagen debido al movimiento del sujeto o del objeto, es decir, a la observación desde puntos de vista diferentes.
Una propuesta en relación con este problema es la de las descripciones estructurales basadas en el objeto, que incluye en la descripción, el marco de referencia perceptivo o eje intrínseco del objeto. De esta forma, al especificar la relación de las partes del objeto con el eje principal del mismo, se mantiene la constancia del objeto.
Cuando la relación entre el objeto y el marco de referencia permanece constante, el reconocimiento del mismo es posible a pesar de los cambios en la imagen. Con la adopción de un marco de referencia intrínseco o centrado en el objeto, e reconocimiento pasa a ser independiente de las transformaciones, así como de los cambios en el punto de vista.
De esta forma, se pueden codificar las relaciones espaciales entre las partes del objeto y el eje principal del mismo y se puede reconocer el objeto cuando se producen cambios de tamaño, posición u orientación.
La excepción a esta regla la constituyen aquellos casos en que existan marcos de referencia alternativos; cuando esto ocurre, el reconocimiento dependerá del marco de referencia seleccionado.
No obstante, la representación basada en el objeto, a saber, la utilización de un sistema de coordenadas espaciales centrado en el objeto. No resuelve todos los problemas apuntados en relación con el reconocimiento. Presenta problemas cuando existe una gran variedad de objetos pertenecientes a una misma clase, cuando el objeto se dobla por alguno de sus ejes, o cuando se les añade alguna parte. En todos estos casos, no se puede obtener un buen ajuste cuando se compara una representación de estas características con os modelos almacenados en la memoria.
Teoría de Marr y Nishihara
Es una teoría del reconocimiento basada en ejes de coordenadas, y se desarrolló en el contexto de la Inteligencia Artificial. La teoría intenta ofrecer una explicación sobre cómo se transforman los patrones estimulares en una representación simbólica en la que se explicitan la forma, orientación, posición, movimiento, etc. de los objetos.
Este procedimiento se desarrolla a través de varias etapas, en las que se generan distintas descripciones del estímulo (esbozo primario, esbozo 2 1⁄2 D y modelo 3D).
La teoría establece también una distinción entre la contribución del procesamiento visual inicial, en el que se generaría el esbozo primario y el esbozo 2 1⁄2 D, y la contribución de procesos posteriores o más tardíos, que llevaría al modelo 3D.
En las dos primeras etapas, el procesamiento es de bajo nivel y no implica ningún proceso de interpretación. En la primera de ellas se crea una representación inicial o “esbozo primario”, en la que se describe la imagen como bordes, manchas, barras y su distribución geométrica. El resultado de esta primera etapa llevaría a una representación de estructuras más globales denomina “esbozo primario completo” que constituye una representación más refinada que la anterior.
En la segunda etapa, se obtiene una representación denominada esbozo 2 1⁄2 D. que aporta información sobre la distancia relativa de las partes de la superficie al observador, su orientación en relación con la línea de división y la presencia de discontinuidades en la superficie. Esto implica que cuando se produce un desplazamiento del sujeto o del objeto, la representación cambia, por lo que todavía resulta inadecuada para la comparación con los modelos almacenados en la memoria. Una representación basada en el punto de vista del observador no es adecuada para describir el objeto.
Para solucionar el problema y mantener la constancia en el reconocimiento del objeto, Marr y Nishihara proponen una tercera etapa de procesamiento tardío, en la que se genera una descripción, denominada modelo 3D, definida a partir de un sistema de coordenadas basado en los ejes naturales del objeto.
Los autores proponen una organización modular de las descripciones del objeto y una representación del objeto basada en primitivos volumétricos que se pueden localizar en los objetos y analizar en términos de ejes de coordenadas.
Los primitivos volumétricos son los conos generalizados, que consisten en las superficies generales a partir del movimiento de una sección transversal a lo largo de un eje principal. La sección puede variar en tamaño pero su forma permanece constante. No todos los objetos pueden describirse mediante conos generalizados como rostros, árboles o plantas.
La teoría propuesta por Marr y Nishihara es un modelo de Inteligencia Artificial, no un modelo capaz de explicar el reconocimiento visual humano.
Modelo de reconocimiento por componentes
Propuesto por Biederman, parte de una idea similar a la de los modelos de reconocimiento de palabras mediante fonemas. La propuesta básica es un modelo de reconocimiento basado en un conjunto finito de primitivos y sus posibles combinaciones, que permiten especificar objetos.
Biederman, propone como primitivos o unidades básicas para el reconocimiento de los objetos, un conjunto finito (aprox. 36) de formas volumétricas simples, que denomina geones.
Propone cuatro tipos de geones básicos: esferas, cilindros, bloques y cuñas, para obtener primitivos tridimensionales a partir de imágenes de entrada bidimensionales. Biederman considera que los geones son características invariantes desde cualquier punto de vista, y pueden utilizarse como material para la construcción de las representaciones tridimensionales.
El supuesto fundamental de la teoría es que los geones pueden diferenciarse sobre la base de propiedades perceptivas de la imagen bidimensional que son independientes del punto de vista que se adopte.
La teoría sugiere además, una serie de relaciones estructurales entre los componentes que permitirían generar múltiples objetos. Por lo tanto, la representación de un objeto consistiría en una descripción estructural que especifica la relación entre los componentes del objeto.
Biederman adopta como base perceptiva para explicar la generación de geones, una propuesta teórica formulada por Loewe, que relaciona la organización perceptiva y el reconocimiento de patrones. El supuesto básico del que se parte es que el sistema visual humano ha desarrollado la capacidad de detectar determinadas organizaciones perceptivas de los elementos de la imagen como simetría, alineamiento, conexión, etc., que no son accidentales. No surgen por casualidad y que se corresponden con propiedades significativas de los objetos.
Las propiedades no accidentales (simetría, paralelismo, rectitud/curvatura, conexión y coterminación), serían las responsables de mantener la constancia del objeto. Las propiedades no accidentales se consideran como características.
Además, las propiedades no accidentales son invariantes, es decir, su correspondencia con el objeto permanece a pesar de los cambios en el punto de vista. El principio básico de organización es que el sistema visual considera que determinadas propiedades de los bordes de la imagen bidimensional constituyen una evidencia de la presencia de esas mismas propiedades en los objetos tridimensionales.
El reconocimiento por componentes procedería de la siguiente forma:
- Primer paso: extracción de borde a partir de los cambios en luminancia. A partir de la información contenida en los bordes, se extraerían las propiedades no accidentales de la imagen que sirve para identificar los geones.
- En paralelo al paso anterior, se llevaría a cabo un proceso de división del objeto en regiones cóncavas, cuyo objetivo es identificar los geones que componen el objeto.
El resultado permitiría especificar el tipo de geones, su posición en la escena, así como las relaciones espaciales ente los mismos. Hasta este punto el procesamiento procedería de abajo-arriba. Una vez activada la descripción de los geones del objeto, se activaría la descripción de los geones almacenados en la memoria y se llevaría a cabo el proceso de comparación en paralelo.
Una serie de estudios experimentales han verificado el funcionamiento del modelo.
Un primer grupo de estudios se dedicó a examinar si el reconocimiento del objeto era más rápido y preciso cuando se presentaban sólo los geones básicos del objeto o cuando se presentaba el objeto perfectamente detallado.
Los dibujos se presentaron a los sujetos durante 100mseg y éstos tenían que nombrar el objeto. Los resultados indicaron que el tiempo de reacción empleado por los sujetos en la tarea de nombrar objetos era aproximadamente igual en los dibujos simples completos e incompletos. Por otra parte, el tiempo de reacción cuando los sujetos tenían que nombrar los dibujos de objetos más complejos fue más corto que en los dos casos anteriores.
Estos resultados apoyan la hipótesis del modelo de reconocimiento por componentes que afirma que los objetos pueden identificarse correctamente a partir de una serie limitada de geones básicos.
Por otra parte. El hecho de obtener una ligera ventaja en el tiempo de reacción ante los objetos complejos se interpretó también como prueba a favor del supuesto de que cuantos más geones contenga un objeto, más rápidamente se llevará a cabo la comparación con las descripciones almacenadas sobre los geones en la memoria.
Un segundo grupo de estudios se dedicó a examinar el efecto de la degradación del estímulo sobre el reconocimiento de los objetos. Se presentaron dibujos completos de los objetos junto con dibujos en los que se degradaron partes fundamentales para la identificación de los geones o partes que no la afectaban. Los resultados mostraron que el reconocimiento empeoraba considerablemente cuando el estímulo presentaba una degradación que afectaba a las propiedades no accidentales.
Cuando la degradación no afectaba a las propiedades no accidentales como en los dibujos de la parte intermedia, se podían identificar los geones a partir de la información existente y reconocer el objeto.
El modelo propuesto por Biederman es más flexible y más apropiado para el reconocimiento humano que el propuesto por Marr y Nishihara presenta la ventaja de que permite contrastar algunas de las hipótesis y los resultados son consistentes con el modelo. Sin embargo, esta teoría también presenta algunas dificultades: no existe hasta el momento ninguna evidencia empírica que apoye la sugerencia de los geones propuestos constituyan la base fundamental para categorizar los objetos.
Modelo PDP de la teoría del reconocimiento por componentes
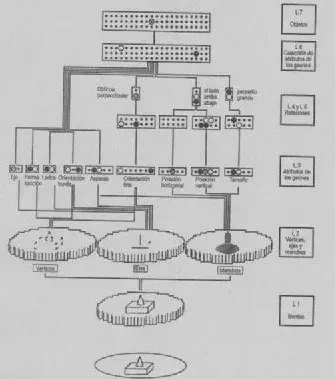
En los modelos PDP se considera que el reconocimiento consiste en la activación de una red formada por unidades de computación artificiales similares a las neuronas, que procesan la información de forma distribuida y en paralelo.
El modelo JIM es una red neuronal conexionista de siete capas.
En la primera capa (L1), formada por un mosaico de células sintonizadas a la orientación y cuyos campos receptivos se solapan, se extraerían los bordes.
En la segunda capa (L2), se extraerían tres tipos de características: vértices, ejes de simetría y manchas, que permiten discriminar entre distintos tipos de geones.
En la capa 3 (L3), se codifican los atributos de los geones.
De esta forma, cada geón queda definido por el valor que presenta en cada uno de estos atributos.
Las capas cuarta y quinta (L4 y L5) reciben la información sobre la posición en el campo visual, tamaño y orientación de los geones, que procede de las células de la capa L3.
En L4 y L5, se especifican las relaciones espaciales entre los geones: orientación, posición y tamaño relativo.
Las células de la capa 6 (L6) reciben las unidades de salida de L3 y L5, que constituyen una descripción estructural de un objeto en términos de los geones que lo componen y las relaciones entre los mismos.
Estas unidades representan el conjunto de todas las descripciones de geones posibles.
En la capa 7 (L7), las células responden a los objetos definidos en base a grupos de células de la capa anterior (L6).
Reconocimiento de caras
La relación ente los elementos componentes de la cara (ojos, boca, nariz, etc.) da lugar a la formación de una configuración en la que se percibe el estímulo como un todo que presenta características propias e independientes de las de sus elementos componentes.
Las caras son estímulos biológica y socialmente importantes, aportando información sobre características relevantes de las personas con las que se interactúa y que pueden influir en el aprendizaje y la interacción social.
El procedimiento experimental básico utilizado en este tipo de estudios, consiste en presentar como estímulos caras construidas artificialmente, en las que se pueden variar las características que forman el rostro.
Las tareas más utilizadas suelen ser las tareas igual-diferentes, en las que los sujetos deben comparar dos caras, o algún componente de las mismas, y señalar si son iguales o no, y atareas de reconocimiento, en las que deben señalar si la cara se había presentado anteriormente.
Procesamiento de las características componentes de las caras
Las primeras investigaciones sobre el reconocimiento de caras partían del supuesto teórico de que el sistema visual analizaba las caras basándose en las características que las componen y a partir de aquí se realizaba una descripción de la cara sobre la base de estas características.
La pregunta básica que surgió en este contexto fue si las diferentes características de las caras se procesaban por separado o si se procesaban como una unidad perceptiva.
La tarea de los observadores consistía en proporcionar juicios “igual-diferente” sobre dos caras presentadas secuencialmente.
Bradshaw y Wallace construyeron caras variando algunas características en cada una de ellas. La tarea de los observadores consistía en proporcionar juicios “igual-diferente” sobre dos caras presentadas secuencialmente.
Los resultados mostraron que el tiempo empleado en emitir un juicio sobre las diferencias de caras era más corto cuanto más características diferentes se presentaban en las caras.
Los autores concluyeron que las características de las caras se procesaban de forma independiente y secuencial y no como una unidad perceptiva. Según esto, los observadores inspeccionarían el pelo en primer lugar, seguido por los ojos, nariz, etc. hasta que encontraban diferencias en las caras.
Sin embargo, los resultados son poco concluyentes debido a dos razones:
- En primer lugar, a las demandas de la tarea utilizada que induce la estrategia de buscar diferencias.
- En segundo lugar, las caras que presentan más diferencias entre sus características también las presentan globalmente, por lo que no se puede excluir que el procesamiento se haya realizado globalmente.
Interacciones entre características componentes en el reconocimiento de caras
Sergent diseñó una serie de estímulos, que consistían en ocho caras distintas resultantes de la combinación de dos barbillas, dos colores diferentes para los ojos, y dos distribuciones distintas del espacio interno de la cara.
En cada ensayo se presentaban dos caras que podían ser iguales o diferir en una única característica o en todas ellas. La tarea de los observadores consistía expulsar una llave de respuesta si las dos caras eran iguales y otra distinta si eran diferentes.
Los resultados confirmaron los obtenidos en estudios anteriores y además demostraron que una cuando las caras diferían en una única característica, las diferencias se percibían más rápidamente cuando dicha característica era la barbilla. Cuando a la diferencia ente barbillas se añadía una de las otras dos, la percepción de la diferencia entre caras era todavía más rápida. Este resultado indicaría que las características componentes de las caras no se perciben independientemente sino que se produce una interacción entre las mismas.
El efecto del contexto se puede manifestar de varia formas como un reconocimiento más preciso de las características componentes cuando se presentan en el contexto de una cara normal que cuando se presentan en el contexto de una cara distorsionada con un patrón de la misma cara almacenado en la memoria ó el efecto de facilitación por parte de patrones bien estructurados de la búsqueda perceptiva de características componentes en caras esquemáticas.
Procesamiento configuracional de las caras
Los resultados de Sergent indican que las características componentes de las caras no se procesan independientemente. El hecho de no sea así indicaría que se procesan como una configuración en el sentido de la Gestalt.
Tanak y Farah partieron de la siguiente hipótesis: si las características componente se representan independientemente en la descripción que el sistema visual hace de la cara, entonces el reconocimiento de las mismas por separado será igual cuando se presenten aisladamente que cuando se presenten en el contexto de una cara. Por el contrario, si la representación de las características no es independiente, se reconocerán peor cuando se presenten aisladamente que cuando se presenten en el contexto de una cara.
El procedimiento utilizado fue: se presentaron a los observadores una serie de caras y durante una serie de ensayos tenían que asociar las caras con un nombre determinado. Una vez aprendidos los nombres de las caras, se presentaba dos prueban re reconocimiento:
En una de ellas, reconocimiento de características componentes en un contexto, se presentaban como estímulos caras que diferían en una única característica y los observadores tenían que indicar si esa característica pertenecía o no a la cara asociada con un nombre determinado en la etapa anterior.
En la otra prueba, reconocimiento de características componentes presentadas aisladamente, se presentaban dos características diferentes y los observadores debían indicar cuál de ellas pertenencia a una cara determinada.
Los resultados indicaron que el reconocimiento de características componentes era peor cuando éstas se presentaban aisladamente que cuando se presentaban en el contexto de caras. Los autores concluyeron que la representación de caras está basada en una descripción global de la imagen que lleva a un mejor reconocimiento de las características componentes en el contexto global de la cara.
Estos resultados difieren de los encontrados con estímulos diferentes como objetos, palabras o caras invertidas, que se reconocen con igual precisión cuando se presentan aisladas o en un contexto global.
Las caras se almacenan globalmente en la memoria, pero no responden a la pregunta de si las caras se perciben globalmente. Las diferencias en el reconocimiento de caras con respecto a otras formas visuales como caras invertidas, objetos o palabras, sugiere que la representación visual de las caras realizada inicialmente en la percepción, puede ser diferente de la representación de otras formas visuales.
Farah, Wilson, Drain y Tanaka realizaron una serie de experimentos en los que incorporaron dos paradigmas perceptivos en lugar de paradigmas de memoria: o Paradigma de de atención selectiva, se presentaban dos caras simultáneamente y los observadores tenían que indicar si una determinada característica era igual o diferente en las dos caras.
La lógica que subyace a la tarea es la siguiente: si el sistema visual proporciona una descripción explícita de las características componentes de las caras, entonces será posible comparar las características presentadas en las dos caras sin ninguna interferencia por parte del resto de características.
Por el contrario, si la representación que proporciona el sistema visual es una representación global, las características a comparar sufrirán interferencia por parte del resto de las características componentes.
Los resultados mostraron una mayor interferencia en la comparación de características cuando las caras se presentaron en posición recta que cuando se presentaron invertidas.
Enmascaramiento, las máscaras presentadas podían ser características componentes de las caras o caras completas, y su finalidad era examinar cuál de estos aspectos distorsionaba más la percepción de caras. Si las caras se perciben como un todo la representación de las características componentes desempeñarían un papel poco importante en el reconocimiento y, por tanto, las máscaras formadas por caras completas distorsionarían más el reconocimiento que las máscaras formadas por caras completas por características componentes.
Se presentaron además otras formas visuales como palabras, objetos y caras invertidas, con el fin de examinar si los efectos eran específicos de la percepción de caras o generales en todos los casos. Los resultados mostraron cuando estaba formada por características componentes.
Los resultados de los experimentos mostraron que la percepción de caras estaba menos basada en la descomposición de partes era más global, que la del resto de formas visuales presentadas.
Las características componentes de las caras no se procesan o codifican de forma independiente sino como una configuración en la que perciben los componentes así como la relación entre los mismos.
Diferencias entre el reconocimiento de caras y objetos
El reconocimiento de caras podría ser un tipo especial de reconocimiento visual.
Los resultados de algunos estudios sugieren que las caras se procesan como un todo, mientras que los objetos y caras invertidas se procesan en base a sus componentes.
Los resultados sobre reconocimiento de patrones invertidos muestran una mayor distorsión en el reconocimiento de caras que en el de objetos.
La comparación entre la distorsión que se produce en el reconocimiento de caras y objetos cuando se presentan invertidos muestra que aunque el reconocimiento de objetos distorsiona cuando se presentan invertidos, el empeoramiento es mucho mayor cuando se tiene que reconocer caras invertidas.
Cuando las caras se presentan invertidas sus características componentes se procesan independientemente y no como una configuración. Las características relacionales se distorsionan cuando las caras se presentan invertidas o con un cambio en la orientación mayor de 90º.
La configuración se distorsiona más que las características componentes cuando se presentan en caras invertidas y que este efecto se debe a un déficit en la codificación de la información configuracional.
Los estudios realizados con registros unicelulares en primates, muestran respuestas selectivas a las caras por parte de neuronas situadas en el girus fusiforme del córtex inferotemporal.
Los estudios realizados con pacientes que presentan lesiones cerebrales, muestran una disociación entre el reconocimiento de objetos y caras. Las lesiones en el girus fusiforme del córtex inferotemporal en el hemisferio derecho, generalmente causan prosopagnosia (incapacidad para reconocer caras) pero prácticamente no afectan al reconocimiento de objetos. La misma lesión en el hemisferio izquierdo, causaría incapacidad para reconocer objetos, pero deja casi intacta la incapacidad para reconocer caras.
La evidencia procedente de estudios en los que se han utilizado técnicas de neuroimagen indica la existencia de distintos componentes modulares en el reconocimiento visual. Los estudios iniciales utilizando la técnica PET, indicaron que determinadas regiones de la vía central se activaban cuando se realizaba una tarea de reconocimiento de caras. Los mismos resultados se obtuvieron utilizando la técnica RMf, que permitía localizar la activación de forma más precisa en dos áreas, el giro fusiforme y el sulcus temporal superior. Un pequeña región del giro fusiforme derecho, se activa selectivamente durante la percepción de caras y no durante la percepción de objetos.
Los resultados anteriores parecen indicar que el conocimiento visual se lleva a cabo por medio de la actuación de mecanismos especializados en determinados tipos de estimulación y no mediante un sistema general y común para todos los tipos de estímulo.
Sin embargo, otros autores defienden que la especialización es superficial ya que el córtex visual contiene un gran número de áreas que responden selectivamente a determinados estímulos.