Qué es la información genética
La cuestión pertinente ahora es establecer cómo se codifica la información en el ADN: se trata de describir cómo se relaciona la secuencia de bases del ADN, lo único que es específico de cada molécula de dicho ácido nucleico, con el fenotipo. Volviendo a Mendel, ¿qué relación hay entre alguna de las moléculas del ADN (genes) del guisante y sus caracteres fenotípicos? Por ejemplo, se sabe que las semillas verdes mantienen ese color verde porque no se degrada la clorofila, mientras que en las amarillas, ésta sí lo hace; o bien, en el caso de la altura de la planta, se sabe que lo que determina la diferencia entre plantas altas y plantas enanas es la longitud del tallo entre nodos, y no el número total de nodos. Estudios genéticos, fisiológicos y analíticos han demostrado en este último caso que en la variante alta interviene una enzima específica, la GA3β-hydroxilasa, enzima que, por alguna razón, es prácticamente inactiva en el caso de las plantas enanas (Smykal, 2014). En 1909, el médico británico A.E. Garrad (1857-1936), publicó su trabajo lnborn errors of metabolism (Errores congénitos del metabolismo), en el que señala que algunas enfermedades hereditarias son causadas por el efecto que la herencia ejerce sobre el metabolismo de determinadas sustancias. Garrad propone un nexo de unión ente genes y fenotipo: el metabolismo. Sin embargo, como suele ocurrir con cierta frecuencia en el ámbito científico, la idea no fue propuesta en el momento adecuado y pasó desapercibida. En 1941, G. Beadle (1903-1989) y E. Tatun (1909-1975), plantearon la hipótesis de un gen/un enzima. Dicha hipótesis afirma que los genes regulan las características fenotípicas de los organismos gracias a que codifican la estructura de las enzimas que intervienen en todos y cada uno de los procesos metabólicos que acontecen en el organismo.
Esta hipótesis fue confirmada con posterioridad, estableciéndose que un gen es la secuencia ordenada de bases nucleotídicas del ADN, la cual secuencia determina a su vez el orden de los aminoácidos de las proteínas. Las proteínas son las sustancias que dan forma a las estructuras orgánicas, y las principales responsables de los procesos metabólicos que explican el funcionamiento de los seres vivos; estas segundas reciben el nombre genérico de enzimas. Ocurre además que las propiedades de las proteínas, curiosamente, dado el paralelismo, vienen determinadas por la secuencia de los aminoácidos, unidades básicas o monómeros de las proteínas.
Los genes que codifican proteínas se denominan genes estructurales para diferenciarlos de aquel las otras secuencias de ADN que portan otro tipo de información, como por ejemplo la de la secuencia de nucleótidos de los distintos ácidos ribonucleicos.
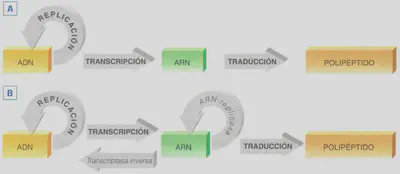
En 1970, Francis Crick, con toda la información disponible acerca las bases moleculares de la herencia, propuso el denominado dogma central de la Biología, que establece el flujo que sigue la información genética, la cual se halla en el ADN (molécula desde la que la información puede ser duplicada para su transmisión a otra célula, a través del proceso de replicación), de donde se trasfiere bioquímicamente a una molécula de ARN, mediante el denominado proceso de transcripción, y desde el ARN, a través del proceso de traducción, la información se expresa en una secuencia polipeptídica. Este dogma central ha tenido que ser ampliado en el sentido de que la información puede almacenarse en forma de ARN y trascribirse inversamente a ADN, siempre siguiendo el sistema de complementariedad de bases: es el caso de los retrovirus, que son virus cuya información genética se almacena en forma de ARN (Fig. 2.17).
La Expresión Génica: la Información en Acción
Para comprender de manera cabal cómo se comporta el material genético, y explicar las bases moleculares de la herencia, lo mejor es describir el proceso que conecta los genes con el fenotipo: estamos hablando de la expresión génica, de la manera en que la información codificada en el ADN se manifiesta en los procesos biológicos que dan lugar al desarrollo y funcionamiento característico de los seres vivos. La información genética, para ser efectiva, ha de seguir un proceso que consta de dos pasos, la trascripción y la traducción.
La Transcripción
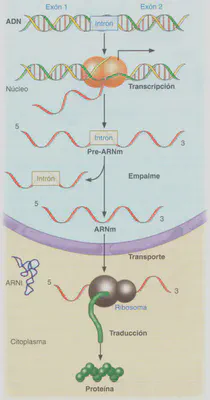
El ADN de los eucariotas se encuentra situado en el núcleo celular, mientras que la maquinaria necesaria para la síntesis de proteínas se halla en el citoplasma. El tamaño de la molécula de ADN y la importancia de la información en ella contenida pueden ser dos de los motivos que hacen que el ADN no viaje hasta el citoplasma para transmitir las instrucciones necesarias para la síntesis proteica. Por ello, cada vez que es necesaria la producción de un determinado polipéptido, la información de su secuencia de aminoácidos es copiada desde el correspondiente gen a un ácido ribonucleico. A este proceso se le denomina transcripción. El ARN formado es el que viaja hasta el citoplasma transportando la información (el mensaje) para que el polipéptido en cuestión sea sintetizado. Por este motivo a ese ARN se le llama ARN mensajero (ARNm).
El proceso de transcripción es catalizado por una enzima perteneciente al grupo de las ARN polimerasas (Fig. 2.18). Como en el caso de la duplicación del ADN, en la transcripción se siguen las reglas de complementariedad, con la salvedad de que en vez de añadir un nucleótido de timina cuando en la hebra molde de ADN aparece un nucleótido de adenina, se añade un nucleótido de uracilo en la cadena de ARN en crecimiento.
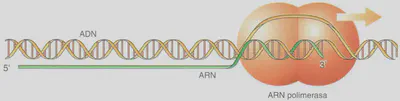
La ARN polimerasa se une a una región específica situada por delante del gen que se va a transcribir, llamada promotor, y desde esta región inicia la síntesis del ARNm. La transcripción del ARN finaliza cuando la ARN polimerasa alcanza una región específica del ADN situada al final del gen, denominada secuencia de fin, que no es otra cosa que una señal de parada de la transcripción. En ese momento, la hebra de ARNm queda libre y la ARN polimerasa se separa del ADN, pudiendo volver a unirse a otro promotor para iniciar una nueva transcripción. Paralelamente, las hebras de ADN separadas para la transcripción, son de nuevo unidas por unas enzimas específicas.
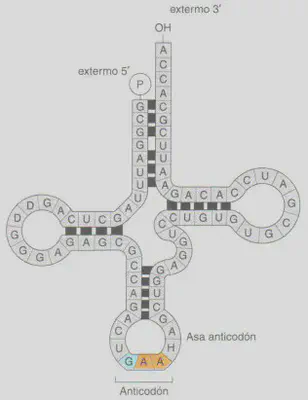
No todas las secuencias de ADN guardan información referente a la estructura primaria de los polipéptidos. Otros segmentos de ADN se transcriben a ácidos ribonucleicos con funciones distintas a la del ARNm. Son ios ácidos ribonucleicos ribosómicos (ARNr), que forman parte del ribosoma, y los ácidos ribonucleicos de transferencia (ARNt), que se encargan de transportar los aminoácidos durante la síntesis de proteínas (Fig. 2.22).
Maduración del ARN
En algunos procariotas y en prácticamente todos los eucariotas, los ARNm experimentan una modificación de su estructura una vez sintetizados (Fig. 2.19). El ARNm que produce la ARN polimerasa se denomina transcrito primario. Éste porta la secuencia que codifica el polipéptido, sin embargo, esta secuencia no está colocada de forma continua en este ARNm, sino disgregada en varias secuencias a lo largo del transcrito primario, separadas por segmentos no codificantes, denominados intrones (secuencias intercaladas), para diferenciarlas de las que sí guardan información, las secuencias codificantes, denominadas exones (las que se expresan). En los eucariotas, los intrones representan un porcentaje mayor de la secuencia génica que el dedicado a los exones. A través de un proceso de corte y empalme (splicing) denominado maduración o procesamiento del transcrito primario, se eliminan los intrones y se colocan secuencialmente los exones, obteniéndose un ARNm maduro que porta la secuencia lineal de un polipéptido funcional. De igual modo, los ARN ribosómicos y de transferencia también experimentan maduración.
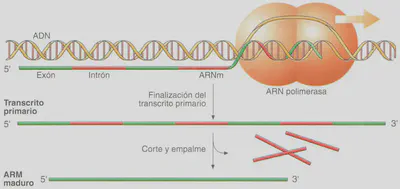
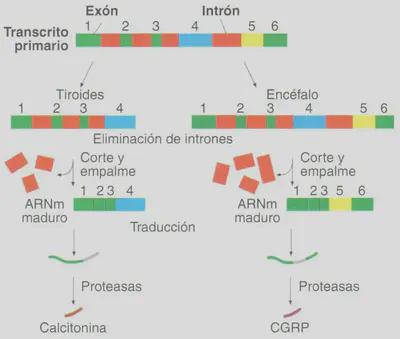
Dependiendo de los genes, hay transcritos primarios que tras su procesamiento codifican siempre ei mismo polipéptido, y otros que pueden experimentar varios tipos de maduración que originan polipéptidos distintos, en función de la célula en que se exprese, y la etapa de desarrollo en que se encuentre el organismo. Por ejemplo, en la rata existe un gen que codifica un transcrito primario que si se expresa en las células del tiroides, origina un ARNm maduro que codifica la secuencia aminoacídica de la hormona calcitonina, mientras que si el procesamiento se realiza en la hipófisis, origina otra hormona, la CGRP (péptido relacionado con el gen de la calcitonina) de efectos diferentes a los de la ca lcitonina (Fig. 2.20).
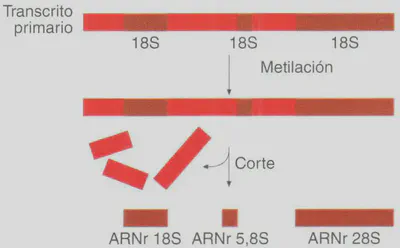
Los ARN ribosómicos y de transferencia también experimentan maduración. Así, en eucariotas, los ARNr 18S, 28S y 5,8S proceden de un solo transcrito primario que tras su maduración origina esos distintos ARNs ribosómicos (Fig. 2.21).
El Lenguaje de la Vida: El Código Genético
Hemos dicho que el ADN contiene la información genética y tiene que haber una característica estructural que le permita hacerlo. A lo largo de los años cuarenta y cincuenta, diversos datos empíricos habían establecido que existía una relación entre la secuencia lineal de nucleótidos del ADN y la de los aminoácidos de los polipéptidos. La pregunta planteada fue ¿cómo está codificada en el ADN la información referente a la secuencia de aminoácidos de un polipéptido? Además, hay que explicar qué pasa en el proceso intermedio de trascripción para que se mantenga la información. Los humanos habitualmente recurrimos al empleo de signos y reglas para guardar información. De esta forma establecemos la equivalencia entre una determinada ordenación de los signos y un significado, es decir, una información concreta. Con la combinación de las 27 letras de nuestro alfabeto podemos formar muchísimas palabras escritas, cada una con un significado. Así, según el orden en que coloquemos las letras A, O, M y R, podremos formar palabras con significado AMOR, MORA, ROMA, RAMO… La información se ha codificado mediante una determinada ordenación de esas cuatro letras: las lenguas tienen códigos para codificar y descodificar la información lingüística, letras, palabras (verbos, sustantivos), frases (sintaxis), etc. Igualmente, el código genético es el conjunto de reglas que permite descifrar la información codificada en el ADN para construir proteínas funcionales y, en general, hacer que la vida de las células sea ordenada y exitosa.
Es sabido que todas las proteínas están constituidas por cadenas de aminoácidos, de los que sólo se usan 20, así que los polipéptidos (proteínas) se diferencian unos de otros sólo por el orden en que estén unidos los aminoácidos que los constituyen. El ADN, por su parte, contiene la información acerca de las secuencias de aminoácidos de todos los polipéptidos del organismo. Dado que la naturaleza del ADN y la de los polipéptidos son distintas, esa información debe ser guardada de forma cifrada de acuerdo con un código. El ADN está formado por sólo 4 nucleótidos cuya diferencia estriba en las bases que los constituyen, Adenina, Timina, Guanina y Citosina, es decir, la información que porta utiliza un alfabeto de cuatro letras (A, T, G y C). Sin embargo, los polipéptidos utilizan 20, y cabe preguntarse cómo es posible que con las 4 letras del ADN se pueda codificar la información relativa a 20 aminoácidos diferentes para formar los polipéptidos.
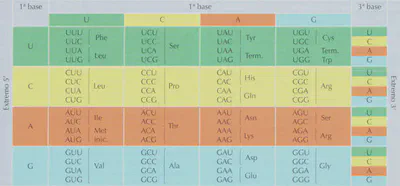
Para encontrar la solución a esta pregunta, y asumiendo que el orden de las bases en el ADN determina el orden de los aminoácidos en las proteínas, los científicos emplearon como primera aproximación la lógica de las técnicas criptográficas para proponer una hipótesis. El ADN debe codificar la información mediante la combinación de sus cuatro tipos de nucleótidos. Si tomamos de una en una las cuatro bases, sólo podremos formar cuatro «palabras » distintas, es decir, el ADN sólo podría guardar información acerca de cuatro aminoácidos. Si el código se estableciese combinando esas cuatro bases de dos en dos, se podrían formar 4² combinaciones posibles, es decir, el ADN podría guardar información acerca de 16 aminoácidos, número de nuevo insuficiente. Si combinamos esas «letras » de tres en tres, se podrán formar 64 «palabras» distintas (4³), número más que suficiente, ya que con 20 hubiese bastado, pero como veremos más adelante, las «palabras » sobrantes también tienen un significado.
Durante los primeros años de la década de 1960 y gracias a los datos experimentales aportados por los grupos de trabajo dirigidos por M. Nirenberg, Severo Ochoa y H.G. Khorana, se comprobó que la base del código genético es el triplete (en el ADN), o codón (cuando nos referimos a ese triplete en el ARNm). Está constituido por una secuencia cualquiera de los tres nucleótidos de los cuatro posibles (de adenina, guanina, citosina y timina; el uracilo sustituye a la timina en el ARNm). El orden en que van los tripletes especifica el orden en que van los aminoácidos en las proteínas. Por tanto, un triplete especifica un aminoácido. La equivalencia entre todos los codones posibles y los distintos aminoácidos que forman parte de los polipéptidos se recoge en la Tabla 2.1: nótese que hay una correspondencia entre cada triplete que forma cada codón del ARNm y los tripletes complementario de una de las dos cadenas del ADN de la que se trascribió, y a la vez, una correspondencia entre la secuencia de codones del ARNm y la secuencia de aminoácidos en la proteína. Para entender de manera cabal cómo funciona el código genético, hay que entender las siguientes propiedades:
- es redundante o degenerado: cada aminoácido puede estar codificado por más de un codón. Habiendo 64 tripletes posibles y sólo 20 aminoácidos, en claro que sobran tripletes: como se ve en la Tabla 2.1, cada aminoácido puede estar codificado por más de un triplete, es decir, hay tripletes «sinónimos». Por ejemplo, el aminoácido arginina es codificado, tanto por el codón AGA, como por el AGG. Además, algunos codones no codifican aminoácidos sino que son señales de paro que hacen finalizar la traducción. Es el caso de los codones UAA, UAG y UGA.
- es un código sin superposición: esto significa que un nucleótido sólo pertenece a un codón y no a varios. Por ejemplo, en la secuencia AUGCAUAAG, los codones serían: AUG, CAU, AAG y no UGC, AUA, GCA o UAA. Es decir, que el nucleótido de guanina del primer codón, por ejemplo, sólo puede pertenecer a ese codón y no a cualquier otro que formemos con los nucleótidos adyacentes.
- la lectura es lineal y continua: con ello se indica que la lectura del ARNm se inicia en un punto y avanza de codón en codón sin interrupciones ni saltos.
- es universal: prácticamente todos los seres vivos, desde una bacteria a un mamífero, pasando por las plantas o los hongos, utilizan el mismo código para traducir el mensaje del ADN a polipéptidos. Esta propiedad apunta claramente hacia una relación de parentesco entre todos los seres vivos.
La Traducción
De la misma forma que la sucesión de palabras codificadas en un lenguaje no tiene otra finalidad que la expresión de una información, el objetivo de todos los procesos descritos hasta aquí es que la información codificada en el ADN se exprese a través de la formación de las proteínas. Al proceso mediante el cual la información contenida en el ARNm, en un alfabeto de cuatro letras, es convertida, siguiendo las reglas del código genético, al alfabeto de 20 letras de los polipéptidos se le denomina traducción. La síntesis del polipéptido cuya secuencia lleva cifrada el ARNm se inicia en los ribosomas. A través de un proceso enzimático, los ácidos ribonucleicos de transferencia (ARNt) (Figura 2.22) van incorporando los correspondientes aminoácidos especificados por la secuencia lineal de codones del ARNm. Esto se consigue gracias a que existen tantos ARNts como codones distintos puede haber en el ARNm. La diferencia entre los ácidos ribonucleicos de transferencia radica en el triplete de nucleótidos complementario de cada uno de los codones del ARNm, denominado anticodón, y en el aminoácido que transporta, que no es otro que el especificado por su codón complementario. El resultado es la formación de un polipéptido con una función biológica concreta y distinta de la de cualquier otro cuya secuencia de aminoácidos sea diferente. Un esquema del proceso de expresión génica se ofrece en la Fig. 2.23.